Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer
Abstract
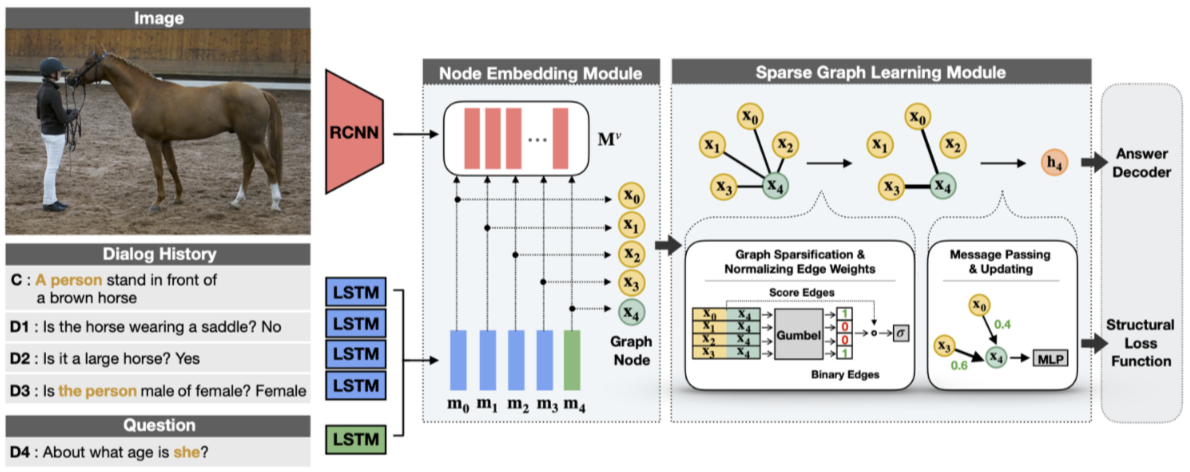
Visual dialog is a task of answering a sequence of questions grounded in an image utilizing a dialog history. Previous studies have implicitly explored the problem of reasoning semantic structures among the history using softmax attention. However, we argue that the softmax attention yields dense structures that could distract to answer the questions requiring partial or even no contextual information. In this paper, we formulate the visual dialog tasks as graph structure learning tasks. To tackle the problem, we propose Sparse Graph Learning Networks (SGLNs) consisting of a multimodal node embedding module and a sparse graph learning module. The proposed model explicitly learn sparse dialog structures by incorporating binary and score edges, leveraging a new structural loss function. Then, it finally outputs the answer, updating each node via a message passing framework. As a result, the proposed model outperforms the state-of-the-art approaches on the VisDial v1.0 dataset, only using 10.95% of the dialog history, as well as improves interpretability compared to baseline methods.