Featured Publications

Polyhedral Complex Derivation from Piecewise Trilinear Networks
Recent advancements in deep neural network visualization reveal insights into mesh extraction from Continuous Piecewise Affine (CPWA) functions, while neural surface representation learning addresses spectral bias but complicates CPWA-based techniques. We focus on trilinear interpolation as positional encoding, showing how hypersurfaces transform into flat planes under the eikonal constraint and introducing a method for approximating intersection points among three hypersurfaces. Empirical validation confirms the correctness and efficiency of our approach through chamfer and angular distance, highlighting the link between eikonal loss and hypersurface planarity.
In NeurIPS,
2024
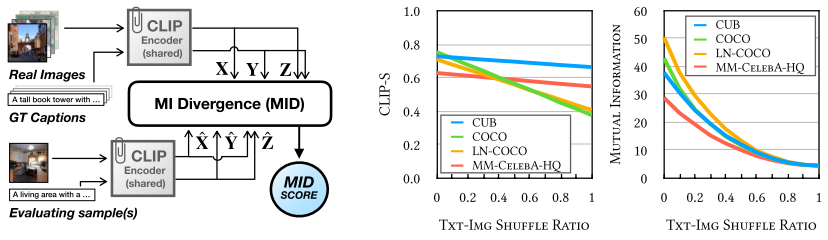
Mutual Information Divergence: A Unified Metric for Multimodal Generative Models
Text-to-image generation and image captioning are recently emerged as a new experimental paradigm to assess machine intelligence. They predict continuous quantity accompanied by their sampling techniques in the generation, making evaluation complicated and intractable to get marginal distributions. Based on a recent trend that multimodal generative evaluations exploit a vison-and-language pre-trained model, we propose the negative Gaussian cross-mutual information using the CLIP features as a unified metric, coined by Mutual Information Divergence (MID). To validate, we extensively compare it with competing metrics using carefully-generated or human-annotated judgments in text-to-image generation and image captioning tasks. The proposed MID significantly outperforms the competitive methods by having consistency across benchmarks, sample parsimony, and robustness toward the exploited CLIP model. We look forward to seeing the underrepresented implications of the Gaussian cross-mutual information in multimodal representation learning and the future works based on this novel proposition.
In NeurIPS,
2022
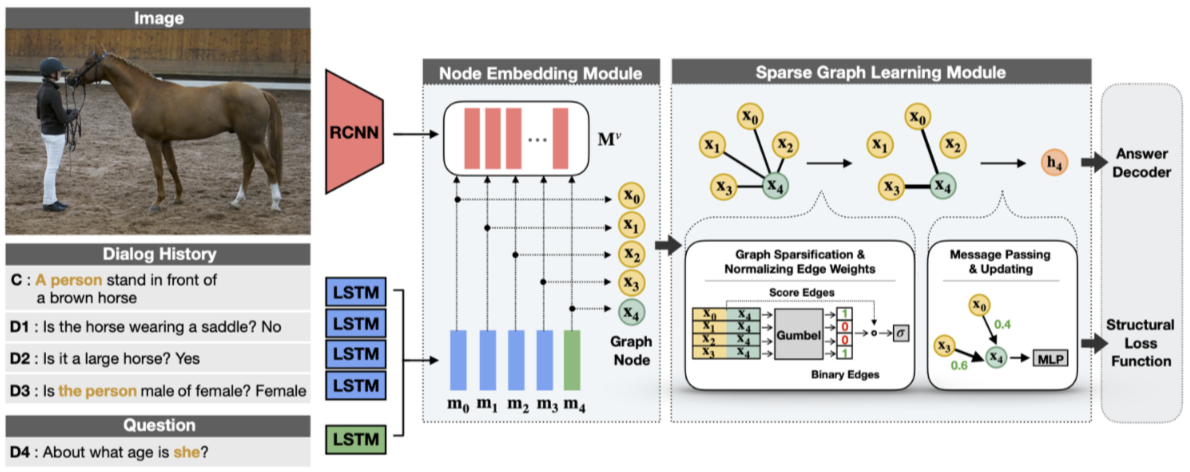
Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer
Visual dialog is a task of answering a sequence of questions grounded in an image utilizing a dialog history. Previous studies have implicitly explored the problem of reasoning semantic structures among the history using softmax attention. However, we argue that the softmax attention yields dense structures that could distract to answer the questions requiring partial or even no contextual information. In this paper, we formulate the visual dialog tasks as graph structure learning tasks. To tackle the problem, we propose Sparse Graph Learning Networks (SGLNs) consisting of a multimodal node embedding module and a sparse graph learning module. The proposed model explicitly learn sparse dialog structures by incorporating binary and score edges, leveraging a new structural loss function. Then, it finally outputs the answer, updating each node via a message passing framework. As a result, the proposed model outperforms the state-of-the-art approaches on the VisDial v1.0 dataset, only using 10.95% of the dialog history, as well as improves interpretability compared to baseline methods.
In Findings of EMNLP,
2021

CoDraw: Collaborative Drawing as a Testbed for Grounded Goal-driven Communication
In this work, we propose a goal-driven collaborative task that combines language, perception, and action. Specifically, we develop a Collaborative image-Drawing game between two agents, called CoDraw. Our game is grounded in a virtual world that contains movable clip art objects. The game involves two players: a Teller and a Drawer. The Teller sees an abstract scene containing multiple clip art pieces in a semantically meaningful configuration, while the Drawer tries to reconstruct the scene on an empty canvas using available clip art pieces. The two players communicate with each other using natural language. We collect the CoDraw dataset of ~10K dialogs consisting of ~138K messages exchanged between human players. We define protocols and metrics to evaluate learned agents in this testbed, highlighting the need for a novel crosstalk evaluation condition which pairs agents trained independently on disjoint subsets of the training data. We present models for our task and benchmark them using both fully automated evaluation and by having them play the game live with humans.
In ACL,
2019
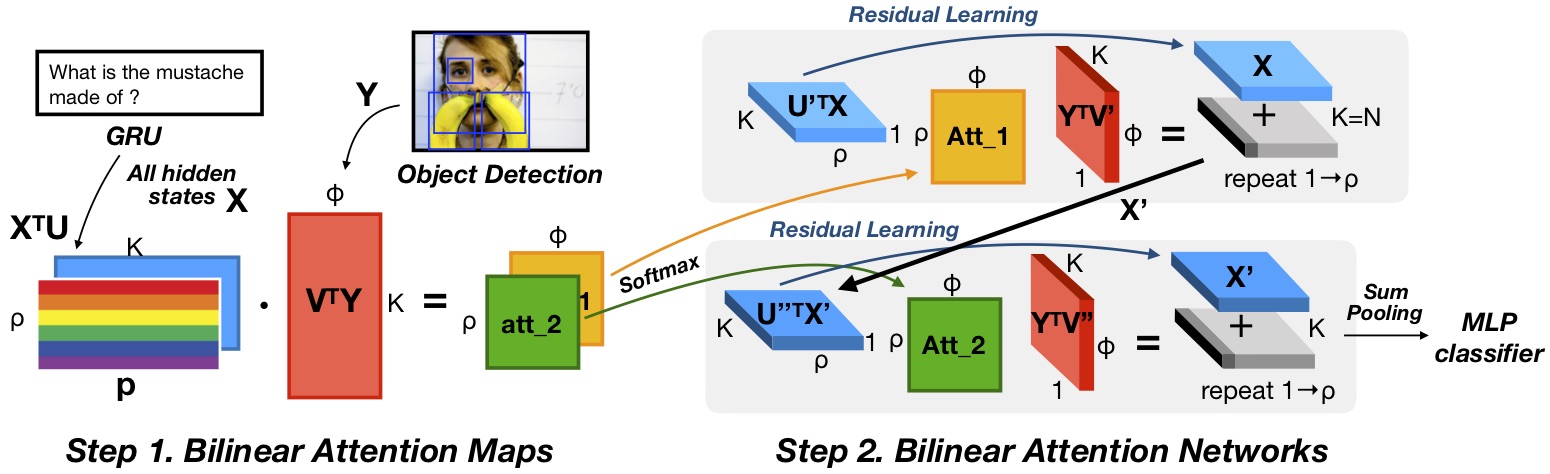
Bilinear Attention Networks
In this paper, we propose bilinear attention networks (BAN) that find bilinear attention distributions to utilize given vision-language information seamlessly. BAN considers bilinear interactions among two groups of input channels, while low-rank bilinear pooling extracts the joint representations for each pair of channels. Furthermore, we propose a variant of multimodal residual networks to exploit eight-attention maps of the BAN efficiently. We quantitatively and qualitatively evaluate our model on visual question answering (VQA 2.0) and Flickr30k Entities datasets. With a simple ensemble of BANs, we won the runners-up in 2018 VQA Challenge while BAN was a winner of single models among the entries.
In NeurIPS,
2018